Autoresearch
Autoresearch is an unattended optimization loop that automatically improves your agent skills through repeated eval cycles. It runs the same evaluate → analyze → improve loop described in the Skill Improvement Workflow, but does it hands-free — no human review between cycles.
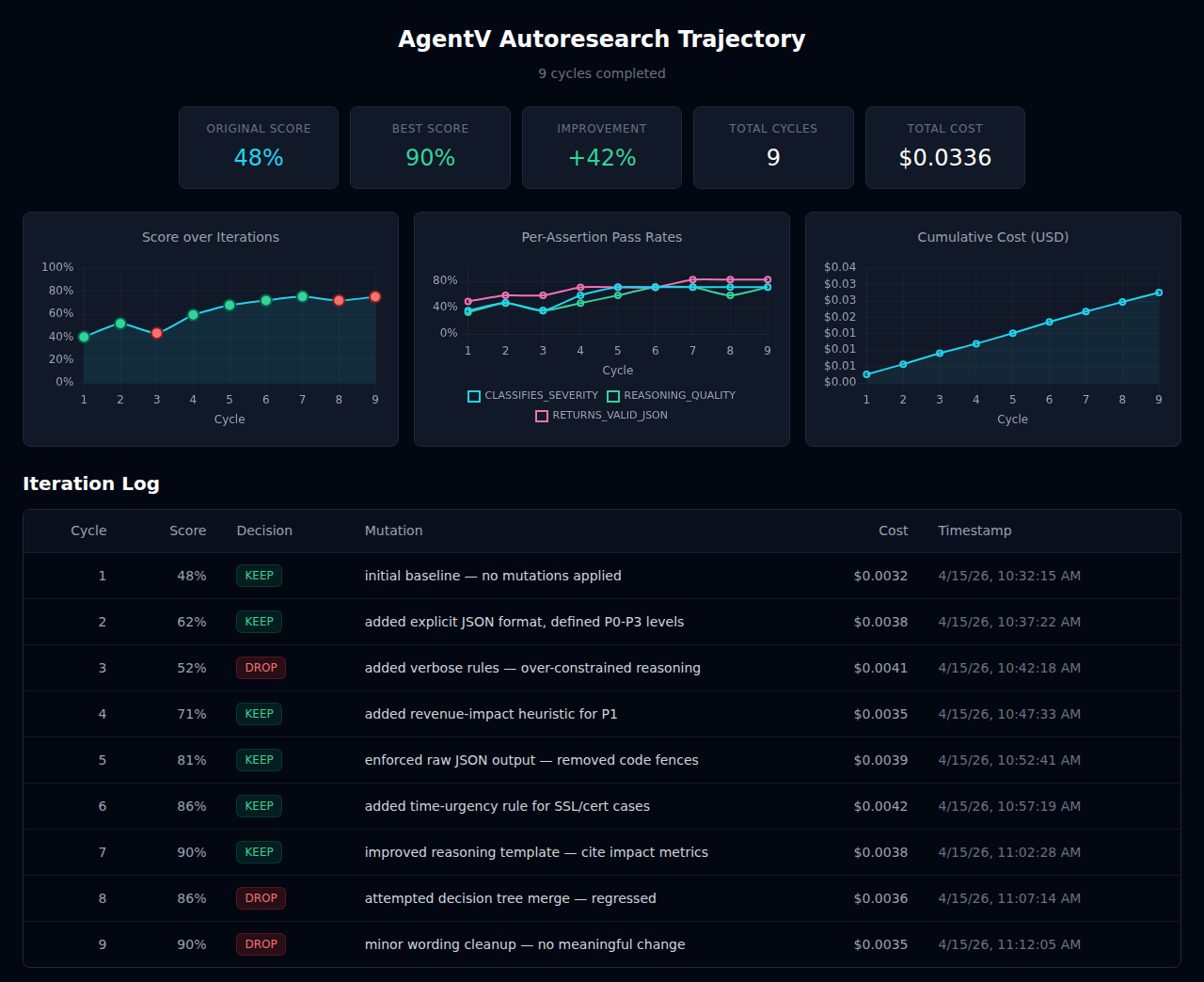
The chart above shows a real optimization run: an incident severity classifier starts at 48% accuracy and reaches 90% after 9 automated cycles — each cycle taking seconds and costing fractions of a cent.
How It Works
Section titled “How It Works” ┌──────────┐ │ 1. EVAL │ ◄───────────────────────────────┐ └─────┬─────┘ │ ▼ │ ┌──────────┐ │ │ 2. ANALYZE│ dispatcher → analyzer subagent │ └─────┬─────┘ │ ▼ │ ┌──────────┐ wins > losses → KEEP │ │ 3. DECIDE │ else → DROP │ └─────┬─────┘ │ ▼ │ ┌──────────┐ │ │ 4. MUTATE │ dispatcher → mutator subagent ──┘ └──────────┘
Stops after 3 consecutive no-improvement cycles or 10 total cycles (configurable).Each cycle:
- Runs
agentv evalagainst the current version of the artifact - Analyzes failures via the analyzer subagent
- Decides keep or discard using
agentv compare --json(automated — no human needed) - Mutates the artifact to address failing assertions, then loops back
The system uses a hill-climbing ratchet: each mutation builds on the best-scoring version, never a failed candidate. Improvements compound; regressions get discarded.
What Gets Optimized
Section titled “What Gets Optimized”Any file or directory artifact: SKILL.md, prompt template, agent config, system prompt, or a directory of related files (e.g., a skill with references/ and agents/ subdirectories). The artifact mode is auto-detected — pass a file path for single-file optimization, or a directory path for multi-file optimization. The mutator rewrites artifacts in place while the eval stays fixed — same test cases, same assertions, different artifact versions.
Prerequisites
Section titled “Prerequisites”- An eval file (EVAL.yaml or evals.json) that covers the behavior you care about
- The artifact must be a file or directory within a git repository (autoresearch uses git for versioning)
- Run at least one manual eval cycle first to validate your test cases
Triggering Autoresearch
Section titled “Triggering Autoresearch”Autoresearch runs through the agentv-bench Claude Code skill. Trigger it with natural language:
"Run autoresearch on my classifier prompt""Optimize this skill unattended for 5 cycles""Run autoresearch on examples/features/autoresearch/EVAL.yaml"No CLI flags or YAML schema changes needed — the skill handles everything.
Output Structure
Section titled “Output Structure”Each autoresearch session creates a self-contained experiment directory:
.agentv/results/runs/autoresearch-<name>/├── _autoresearch/│ ├── iterations.jsonl # Per-cycle data (score, decision, mutation)│ └── trajectory.html # Live-updating Chart.js visualization├── 2026-04-15T10-30-00/ # Cycle 1 run artifacts│ ├── index.jsonl│ ├── grading.json│ └── timing.json├── 2026-04-15T10-35-00/ # Cycle 2 run artifacts│ └── ...└── ...Autoresearch uses git-based versioning instead of backup files. Each successful mutation is committed (git add && git commit), and failed mutations are reverted (git checkout). The optimized artifact lives in the working tree and the latest commit — no separate best.md to copy.
_autoresearch/trajectory.html— Open in a browser to see the score trajectory, per-assertion breakdown, and cumulative cost. Auto-refreshes during the loop, becomes static on completion._autoresearch/iterations.jsonl— Machine-readable log of every cycle for downstream analysis.
Review the mutation history with git log after the run completes.
The Keep/Drop Decision
Section titled “The Keep/Drop Decision”After each eval cycle, autoresearch runs agentv compare between the current candidate and the best baseline:
agentv compare <baseline>/index.jsonl <candidate>/index.jsonl --jsonThe decision rule:
| Condition | Decision | Outcome |
|---|---|---|
wins > losses | KEEP | Promote to new baseline, reset convergence counter |
wins <= losses | DROP | Revert to best version, increment convergence counter |
mean_delta == 0, simpler artifact | KEEP | Simpler is better at equal performance |
Three consecutive DROPs trigger convergence — the optimizer stops because it can’t find improvements.
Example: Incident Severity Classifier
Section titled “Example: Incident Severity Classifier”Here’s a real scenario showing autoresearch in action. We start with a minimal classifier prompt:
# classifier-prompt.md (initial version)Classify the incident into P0, P1, P2, or P3.Give your answer as JSON with severity and reasoning fields.And an eval with 7 test cases covering edge cases — payment failures, SSL cert expiry, gradual memory leaks:
# EVAL.yaml (stays fixed — only the prompt changes)tests: - id: total-outage assertions: - type: contains value: '"P0"' - type: is-json - "Reasoning mentions complete service outage" - id: payment-failures assertions: - type: contains value: '"P1"' - type: is-json - "Reasoning weighs revenue impact despite intermittent nature" # ... 5 more test casesRunning autoresearch produces this trajectory:
Cycle Score Decision Mutation───── ───── ──────── ────────────────────────────────────── 1 0.48 KEEP initial baseline — no mutations applied 2 0.62 KEEP added explicit JSON format, defined P0-P3 levels 3 0.52 DROP added verbose rules — over-constrained reasoning 4 0.71 KEEP added revenue-impact heuristic for P1 5 0.81 KEEP enforced raw JSON output — removed code fences 6 0.86 KEEP added time-urgency rule for SSL/cert cases 7 0.90 KEEP improved reasoning template — cite impact metrics 8 0.86 DROP attempted decision tree merge — regressed 9 0.90 DROP minor wording cleanup — no meaningful change ↳ 3 consecutive drops → CONVERGEDResult: 0.48 → 0.90 (+42 points) in 9 cycles, $0.03 total cost. The optimized prompt is in the working tree (and the latest git commit).
Key observations:
- Cycle 3 shows a failed mutation (verbose rules hurt reasoning) — the ratchet discarded it and continued from the cycle 2 version
- Cycles 8–9 show convergence — the optimizer couldn’t improve further and stopped automatically
- Per-assertion tracking reveals which aspects improved: classification accuracy reached 100% by cycle 6, while JSON format compliance and reasoning quality improved more gradually
Convergence
Section titled “Convergence”Autoresearch stops when either condition is met:
- 3 consecutive no-improvement cycles (configurable) — the optimizer has converged
- 10 total cycles (configurable) — hard limit to bound cost
You can override both limits when triggering autoresearch:
"Run autoresearch with max 20 cycles and convergence threshold of 5"Best Practices
Section titled “Best Practices”Start manual, then automate. Run 2-3 manual eval cycles to validate your test cases catch real issues. Once you trust the eval, switch to autoresearch.
Same-model pairings work best. The meta-agent running autoresearch should match the model used by the task agent (e.g., Claude optimizing a Claude agent). Same-model pairings produce better mutations because the optimizer has implicit knowledge of how the target model interprets instructions.
Watch the per-assertion chart. If one assertion is stuck at 0% while others improve, the eval may be too strict or testing something the prompt can’t control. Consider adjusting the assertion.
Review the optimized artifact. Autoresearch improves scores, but always review the changes (git diff <initial_sha>) before adopting them. The optimizer may have found a valid but unexpected approach.
Keep artifact directories focused. For directory mode, keep artifacts to 5–15 files. The mutator works best when it can reason about the full scope without reading dozens of files. Split large skill directories if needed.
Relationship to Manual Workflow
Section titled “Relationship to Manual Workflow”| Aspect | Manual Loop | Autoresearch |
|---|---|---|
| Human checkpoints | Every iteration | None (opted in to unattended) |
| Keep/discard | You decide | Automated via agentv compare |
| Mutation | You edit the skill | Mutator subagent rewrites |
| Max iterations | Unbounded | 10 cycles or convergence |
| Best for | Building eval intuition | Scaling optimization |
| Trajectory chart | Not included | Auto-generated with live refresh |
Start with the manual loop to understand the workflow, then use autoresearch to scale it.